
¿Que es Deepspeech2?
Deepspeech2 son una serie de modelos de reconocimiento de voz (ASR) con una arquitectura similar que están basados en Baidu DeepSpeech2. Es uno de los modelos más utilizados en el mundo del reconocimiento de voz dado que no es muy pesado y tiene buen rendimiento, por lo que puede usarse en tiempo real sin necesidad de un coste elevado.
Por el contrario, otro tipo de modelos más complejos como por ejemplo Wav2vec2, son más costosos de llevarlos a producción, aunque normalmente se obtengan mejores resultados.
Deepspeech2 sigue la siguiente arquitectura:
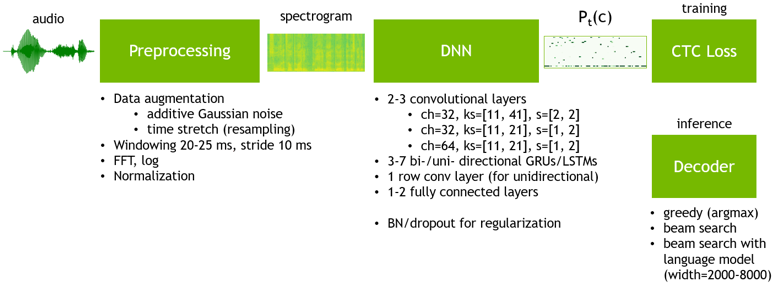
¿Cómo entrenar Deepspeech2 desde cero?
Para poder entrenar Deepspeech2 debemos de disponer de un dataset de audios con el texto transcrito.
Para los idiomas más comunes podemos echar mano del proyecto Common Voice, que nos puede proporcionar cientos de horas de audio en diversas lenguas. Si disponemos de un conjunto de datos propio, deberemos de trocear los audios en no más de 15/20 segundos y es recomendable transformarlo a 16kHz.
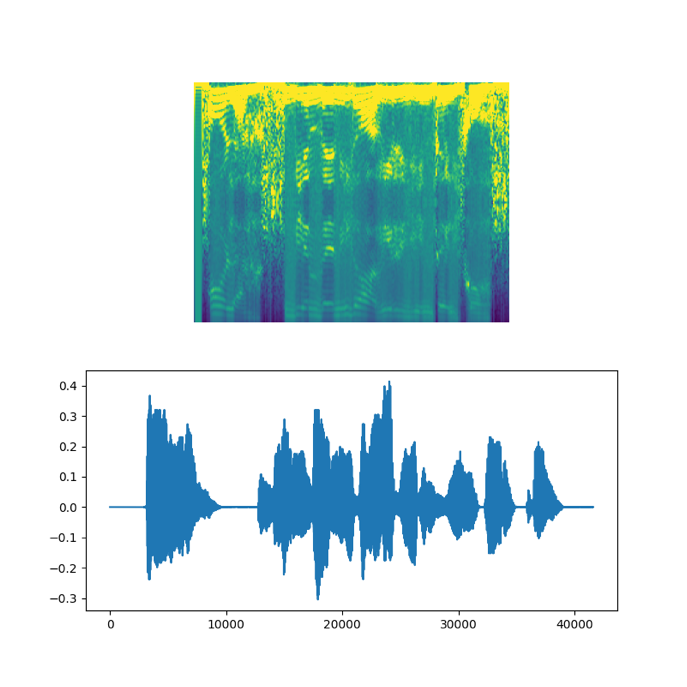
Una vez tenemos nuestros audios, vamos a obtener el espectrograma de cada uno de ellos. De esta manera, tendremos la representación gráfica de un audio, que depende la intensidad y frecuencia en función del tiempo.
Es decir, tenemos la información de la intensidad y frecuencia de un audio en un periodo de tiempo determinado y todo ello en forma de imagen. Estas imágenes serán el input de nuestro modelo. Para obtenerlo, nos podemos ayudar de una de las librerías mas utilizadas en el ámbito del Deep Learning como es Tensorflow.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
file = tf.io.read_file(wav_file)
audio, _ = tf.audio.decode_wav(file)
audio = tf.squeeze(audio, axis=-1)
audio = tf.cast(audio, tf.float32)
spectrogram = tf.signal.stft(
audio, frame_length=frame_length, frame_step=frame_step, fft_length=fft_length
)
spectrogram = tf.abs(spectrogram)
spectrogram = tf.math.pow(spectrogram, 0.5)
means = tf.math.reduce_mean(spectrogram, 1, keepdims=True)
stddevs = tf.math.reduce_std(spectrogram, 1, keepdims=True)
spectrogram = (spectrogram - means) / (stddevs + 1e-10)
spectrogram = spectrogram.numpy()
spectrogram = np.array([np.trim_zeros(x) for x in np.transpose(spectrogram)])
fig = plt.figure(figsize=(8, 8))
ax = plt.subplot(2, 1, 1)
ax.imshow(spectrogram, vmax=1)
ax.axis("off")
ax = plt.subplot(2, 1, 2)
plt.plot(audio)
plt.show()
Ahora vamos a definir la arquitectura de nuestra red, para ello nos volvemos a ayudar de la librería Tensorflow y Keras.
from tensorflow.keras import layers
from tensorflow import keras
CHARACTERS = [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z', 'á', 'é', 'í', 'ñ', 'ó', 'ú', 'ü']
input_dim = fft_length // 2 + 1
output_dim = len(CHARACTERS) + 1
#Dos o tres capas convolucionales
input_spectrogram = layers.Input((None, input_dim), name="input")
x = layers.Reshape((-1, input_dim, 1), name="expand_dim")(input_spectrogram)
x = layers.Conv2D(filters=32, kernel_size=[11, 41], strides=[2, 2], padding="same",
use_bias=False,name="conv_1",)(x)
x = layers.BatchNormalization(name="conv_1_bn")(x)
x = layers.ReLU(name="conv_1_relu")(x)
x = layers.Conv2D(filters=32, kernel_size=[11, 21], strides=[1, 2], padding="same",
use_bias=False, name="conv_2",)(x)
x = layers.BatchNormalization(name="conv_2_bn")(x)
x = layers.ReLU(name="conv_2_relu")(x)
x = layers.Reshape((-1, x.shape[-2] * x.shape[-1]))(x)
# De 5 a 7 capas recurrentes
for i in range(1, 5 + 1):
recurrent = layers.GRU(units=1024, activation="tanh", recurrent_activation="sigmoid",
use_bias=True, return_sequences=True, reset_after=True, name=f"gru_{i}",)
x = layers.Bidirectional(recurrent, name=f"bidirectional_{i}", merge_mode="concat")(x)
if i < 5:
x = layers.Dropout(rate=0.5, name=f"dropout_{i}")(x)
x = layers.Dense(units=1024 * 2, name="dense_1")(x)
x = layers.ReLU(name="dense_1_relu")(x)
x = layers.Dropout(rate=0.5, name=f"dropout_{i+1}")(x)
# Capa de clasificación
output = layers.Dense(units=output_dim, activation="softmax")(x)
# Model
model = keras.Model(input_spectrogram, output, name="DeepSpeech_2")
Primero se definen las capas convolucionales (en nuestro caso dos), que son las encargadas de extraer las características del espectrograma. Es decir, las características de los fonemas según las intensidades y frecuencias del locutor. Después le siguen las capas recurrentes y las capas fully connect, que son las encargadas de clasificar cada carácter.
La última capa que vemos tiene la longitud de nuestra lista de caracteres más uno, ya que para entrenar nuestro modelo usaremos la función de pérdida CTC (Connectionist Temporal Classification) y necesita un símbolo para el “vacío”. Esta última capa nos dará las “probabilidades” (confianza) de cada uno de los caracteres y a partir de esto aplicaremos un algoritmo de decodificación para poder inferir.
Ya tenemos la estructura del modelo, pero para poder entrenarlo debemos de definir la función de pérdida, que será la mencionada CTC. De nuevo, nos ayudamos de Tensorflow.
def CTCLoss(y_true, y_pred):
batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64")
input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64")
label_length = tf.cast(tf.shape(y_true)[1], dtype="int64")
input_length = input_length * tf.ones(shape=(batch_len, 1), dtype="int64")
label_length = label_length * tf.ones(shape=(batch_len, 1), dtype="int64")
loss = keras.backend.ctc_batch_cost(y_true, y_pred, input_length, label_length)
return loss
model.compile(optimizer=keras.optimizers.Adam(), loss=CTCLoss)
Faltaría por definir los últimos hiperparámetros (batch size, learning rate, callbacks…), disponer de una tarjeta gráfica, un poco de paciencia y ya estaríamos preparados para entrenar nuestro modelo de reconocimiento de voz.
Una vez entrenado, ¿cómo inferimos?
Una parte importante de los modelos de reconocimiento de voz, así como otros tipos de modelos secuenciales como los de OCR (optical character recognition), es la decodificación posterior a la inferencia.
Recordemos que el resultado del modelo es una secuencia con las confianzas de cada uno de los caracteres y lo que queremos es pasarlo a texto. Existen varias formas de decodificar nuestro modelo, y entre ellas podemos encontrar las siguientes:
Decodificación greedy
Consiste en tomar el valor máximo de cada carácter en cada momento de tiempo, después eliminamos caracteres duplicados y por último borramos el carácter del CTC. Como se puede ver en la siguiente imagen:
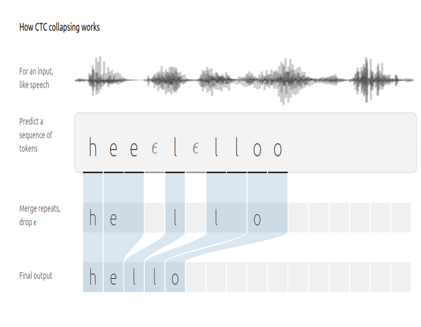
Esta solución es bastante aceptable, además es muy rápida de computar, pero tiene varios inconvenientes. Por ejemplo, sufre bastante con errores ortográficos o palabras homófonas (“vaca” y “baca”), ya que no va a ser capaz de diferenciarlas y se puede confundir.
Beam Search con modelos de lenguaje
Uno de los algoritmos más usados es unir “beam search” con modelos de lenguaje. De esta manera, seremos capaces de corregir errores como los que hemos comentado.
Lo que nos devuelve un modelo de lenguaje es la probabilidad de que una cadena de caracteres sea posible en base a un Corpus. Además, incorporando la estrategia “beam search” obtendremos varias secuencias y no solo la de máxima probabilidad, por lo que luego nos podemos quedar con la que mejor se adapte a nuestro modelo de lenguaje.
Para utilizar un modelo de lenguaje de manera rápida y eficiente nos podemos ayudar de la librería pyctcdecode. Podemos utilizar un modelo ya preentrenado o entrenar el nuestro, aunque necesitamos una gran cantidad de textos para obtener buenos resultados.
path_kenlm = "kenlm_sp.arpa"
from pyctcdecode import build_ctcdecoder
decoder = build_ctcdecoder(
CHARACTERS,
path_kenlm,
alpha=0.5,
beta=1.0,
)
X, y = batch
batch_predictions = model.predict(X)
text = decoder.decode(batch_predictions[0])
También podemos añadir “hotwords” a nuestro decodificador, de esta forma le dará un peso mayor a estas palabras y podremos corregir errores ortográficos. Esto puede ser muy útil cuando trabajamos en un dominio muy concreto (marcas de coche), o con palabras que a priori nuestro modelo no va a conocer pero se pueden estar usando en este momento (ej. “covid”).
Hay que tener en cuenta que si abusamos de su uso, esto nos puede llevar a cometer errores. A continuación podemos ver varios ejemplos del resultado del modelo utilizando los dos algoritmos.
real: 'como los ciervos llevan la cifra de su edad en cada rama' greedy: 'como los cierobos llevan la cifra de su edad en cada rama' beam search lm: 'como los ciervos llevan la cifra de su edad en cada rama' real: 'conducía sus ovejas cantando una tonada sentida y armoniosa' greedy: 'conducía sus obejas cantando una tonada sentida y armoniosa' beam search lm: 'conducía sus ovejas cantando una tonada sentida y armoniosa' real: 'él nos vio y al punto vino corriendo para abrazarnos a todos con mucha alegría' greedy: 'él nos vio y al punto vino corriendo para brazarnos a todos con mucha alegría' beam search lm: 'él nos vio y al punto vino corriendo para abrazarnos a todos con mucha alegría'
Como se puede ver nuestro modelo de lenguaje ha sido capaz de corregir errores que el algoritmo greedy comete. Por ejemplo, en la palabra “oveja”, ya que la “b” suena igual que la “v” nuestro modelo se confunde y el carácter de mayor confianza es la “b”, gracias a nuestro modelo de lenguaje podemos corregirlo.
Una de las métricas más usadas para medir la eficacia de modelos de reconocimiento de voz es el WER (word error rating). En nuestro modelo base, el WER con el algoritmo greedy es de 20% mientras que con el modelo de lenguaje es del 11%: es una mejora bastante considerable ya que casi se reduce a la mitad el error cometido.
Conclusión
Hemos visto como entrenar un modelo de reconocimiento de voz con Tensorflow, particularmente con la estructura Deepspeech2 y los problemas que pueden surgir en este tipo de modelos.
Para poder corregir errores se pueden usar modelos de lenguaje a la hora decodificar. Esta es una técnica muy recomendable ya que nos permite mejorar nuestro WER sin la necesidad de realizar un entrenamiento nuevo.
Para ampliar:
• https://keras.io/examples/audio/ctc_asr/
• https://www.youtube.com/watch?v=mp7fHMTnK9A
• https://distill.pub/2017/ctc/
• https://nvidia.github.io/OpenSeq2Seq/html/speech-recognition/deepspeech2.html