
Diseñando una infraestructura en alta disponibilidad
Un aumento de tráfico en nuestra web puede ocasionar problemas de rendimiento, y por tanto de crecimiento, para solventar esta casuística vamos a diseñar y planificar el lanzamiento de una infraestructura webDesde el Departamento de Sistemas de Ipglobal nos gustaría compartir durante una serie de artículos los procesos que seguimos en el diseño de nuestras infraestructuras.
Diseñando infraestructuras de alta disponibilidad
A la hora de diseñar una infraestructura debemos tener presentes una serie de reglas que no siempre vendrán determinadas pero que nosotros consideramos importantes:
Alta disponibilidad
Cuando se menciona el concepto de alta disponibilidad suele venir a la mente que nuestra plataforma web o servicio esté siempre disponible, así que debemos asegurar que todos los puntos de fallo estén redundados desde la capa más baja hasta la más alta; de lo contrario, un fallo tan simple como una caída de nuestra línea de internet, router, firewall, electrónica de red o almacenamiento podría provocar que todo el diseño implementado en la infraestructura de servidores nos amargue el día.
Ilustraremos esta reflexión con unos ejemplos que comentaremos:
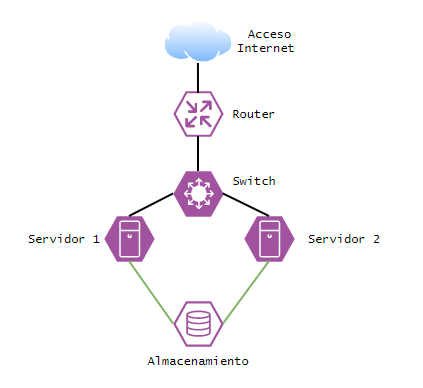
Ilustración 1. Diagrama infraestructura básica
Esta primera ilustración nos muestra una infraestructura básica en la que tenemos un proveedor de internet, un router, un switch, dos servidores y una cabina de almacenamiento.
El primer punto de fallo, siguiendo el diagrama desde arriba hacia abajo, sería que sólo disponemos de un proveedor de internet, por lo que en caso de que este proveedor tenga alguna incidencia o problema, nuestra infraestructura no sería accesible; por ahora no vamos a mencionar temas de resolución DNS, eso lo veremos mucho más adelante (DNS Round-Robin).
El segundo punto de fallo sería que sólo disponemos de un router, por lo que ante una incidencia hardware sobre el mismo, aunque nuestro proveedor de internet esté operativo, nuestra infraestructura no sería accesible.
Bajando en el diagrama el siguiente fallo sería nuestro switch de core, sólo disponemos de uno y podría verse afectado por una incidencia en el hardware.
A nivel de servidores, hemos comenzado bien, tenemos dos servidores por lo que si uno falla podríamos tener otro operativo, pero ambos obtienen su almacenamiento de la misma cabina, por lo que ante un error de esta última nos encontraríamos una vez más con que nuestra infraestructura no sería accesible.
Ilustraremos este detalle con un flujograma:
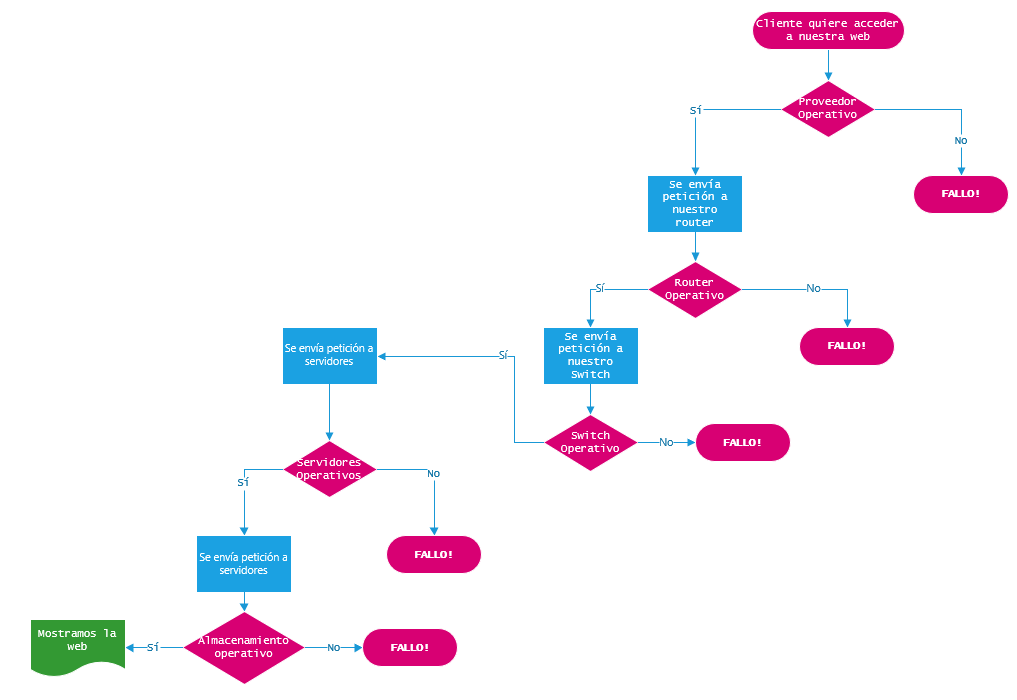 Ilustración 2. Flujograma puntos de fallo
Ilustración 2. Flujograma puntos de fallo
Es de vital importancia tener en cuenta cualquier punto de fallo y no dar ninguno por sentado. A continuación, presentamos un diagrama ilustrativo de una infraestructura base que nos asegure los principales puntos de error del anterior diagrama.
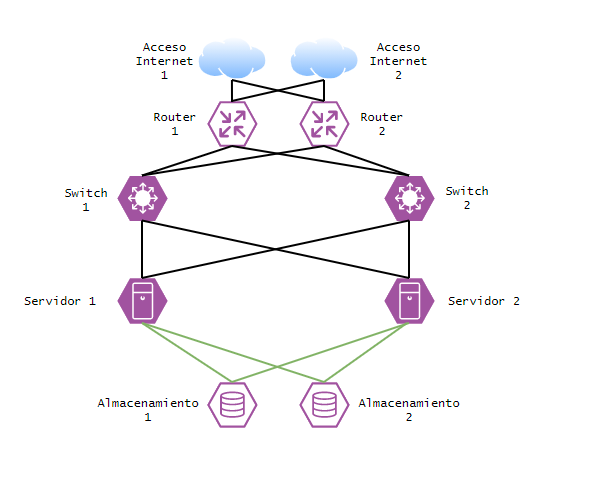 Ilustración 3. Diagrama infraestructura redundada
Ilustración 3. Diagrama infraestructura redundada
En este diagrama, sin tener en cuenta el número de servidores o la infraestructura de servidores que compondrán nuestra plataforma web, podemos asegurar que ante una incidencia, bien sea por parte de nuestro proveedor de internet o una avería hardware en alguno de los dispositivos de red o almacenamiento, siempre tendremos disponible el acceso a nuestros servidores y por tanto a nuestra plataforma web.
Por tanto, el principio de alta disponibilidad debemos seguir escalándolo al diseñar la infraestructura que compondrá nuestra plataforma web.
Escalabilidad
Cuando queremos escalar una infraestructura para agregar así recursos adicionales, debemos tener en cuenta en todo momento los dos enfoques posibles de escalabilidad, ya que en algunas ocasiones podremos utilizar uno u otro:
- Escalabilidad vertical: Este tipo de escalado implica agregar más recursos hardware a los servidores existentes en el diseño; como podría ser la ampliación de memoria RAM, CPU’s o almacenamiento.
- Escalabilidad horizontal: En este tipo de escalado agregaremos más servidores en las capas que lo necesiten, pudiendo así repartir la carga.
La escalabilidad vertical dentro de infraestructuras virtuales es algo sencillo, siempre y cuando tengamos los recursos, pero debemos diseñar tanto nuestra aplicación como infraestructura para una escalabilidad horizontal que nos permita agregar más servidores a la plataforma en cuanto lo necesitemos y así poder mantener el principio de alta disponibilidad.
Hay que contar que la escalabilidad vertical, solemos tomarla como un recurso sencillo agregando más memoria RAM al servidor, pero podría comenzar a limitarnos la CPU, interface de red o las IOPS* (entradas y salidas del acceso a disco). Por tanto, cualquier aumento o escalabilidad que hagamos de manera vertical debe ser compensada y analizada antes de ejecutarla, ya que aumentar la capacidad o rendimiento de algunos componentes podría volverse una tarea bastante tediosa si no la hemos planificado correctamente o incluso podría volverse contraproducente, y en vez de obtener una mejora de rendimiento, obtener una degradación del servicio por un cuello de botella en otro punto no compensado.
*IOPS (I/O per second): Operaciones de entrada/salida por segundo que se realizan en una unidad de almacenamiento, por tanto, a mayor valor, mejor es el rendimiento general. Los valores de IOPS pueden variar según el tipo de almacenamiento, siendo mayor en unidades de almacenamiento de estado sólido y menor en unidades de almacenamiento mecánico. También puede verse penalizado por el tipo de configuración RAID* que empleemos.
*RAID: Es el acrónimo del inglés Redundant Array of Independent Disks, cuya finalidad es crear un único volumen con varios discos duros. Según el tipo de RAID que se defina, puede llegar a proporcionar redundancia de datos y de esta manera proteger la información en caso de que uno de los discos duros falle o puede ser definido para que estos discos trabajen en conjunto, obteniendo así una mayor velocidad.

Si tomamos como único enfoque la escalabilidad vertical y vamos aumentando recursos a nuestro único servidor, llegando a tener un auténtico monstruo hardware, llegará el momento en el que realizar cualquier actuación sencilla como la aplicación de actualizaciones, reinicio por mantenimiento o un simple fallo de sistema, nos provoquen un dolor de cabeza innecesario ya que nos podrían surgir las siguientes cuestiones:
- ¿Cuál es la mejor hora del día para reiniciar el servidor?
- ¿Hemos probado todas las actualizaciones que queremos aplicar en un entorno igual para verificar que todo mantiene su funcionamiento correcto?
El enfoque de escalabilidad horizontal también tiene puntos que deben ser analizados, ya que decidir el momento en el que escalar es mucho más complicado que definir cómo escalar.
Hoy en día nos podemos encontrar plataformas que escalan automáticamente de manera horizontal definiendo reglas según eventos del tipo “Si superamos 10.000 visitas concurrentes añades un nuevo servidor web”. Bajo esta regla, repartirán la carga de las peticiones web entre más servidores, por lo que serían atendidas más rápido, pero podrían no responder a la misma velocidad si se ha generado un cuello de botella en capas inferiores si el resto de plataforma no escala proporcionalmente.
Ejemplo:
Generamos una regla automática que nos despliegue un nuevo servidor web cuando superamos un número X de “visitas” por segundo. Este nuevo servidor web estaría dado de alta en un servicio de balanceo que repartiría la carga entre los distintos servidores desplegados.
Sin profundizar más, sólo hemos configurado que nos despliegue servidores web, pero no más nodos de nuestro servidor de base de datos, lo que terminará provocando que un único servidor atienda las peticiones de N servidores.
Esta situación terminará provocando un efecto de embudo, donde por la parte superior (servidores web) atendemos muy rápido las peticiones de los usuarios, pero cuando nuestros servidores web precisan consultar información en la base de datos que está alojada en un único servidor, sólo tendrán un punto de consulta y un único punto de respuesta, por lo que recibirán los datos posiblemente más lento y los usuarios denotarán un tiempo de respuesta poco idóneo.
Categorización o clasificación
Cuando se nos presenta el momento de diseñar una infraestructura, debemos tener en cuenta la categorización de los servicios que necesitará esta plataforma, por ejemplo, en una plataforma web podemos diferenciar dos servicios principales que segregaremos en servicio web y base de datos.
El servicio web atenderá las peticiones entrantes de los usuarios, procesará el código con el que hemos desarrollado nuestra aplicación y devolverá los resultados.
Por el contrario, el servicio de base de datos atenderá las peticiones que se realicen desde el código con el que tengamos desarrollada nuestra aplicación.
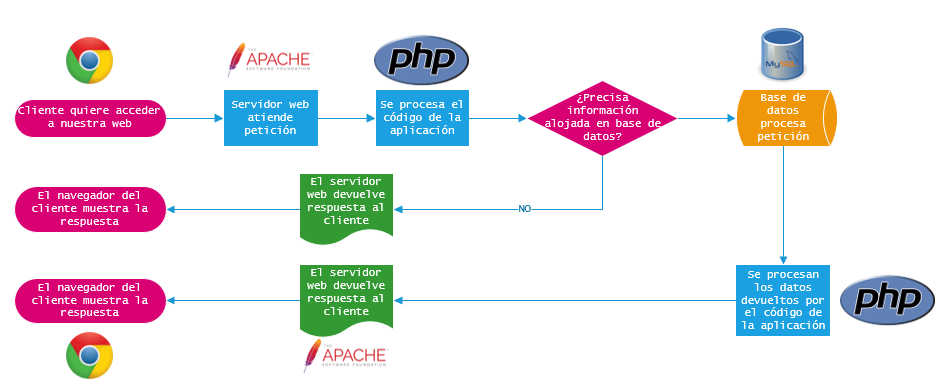 Ilustración 4. Proceso servicio servidor web Apache + PHP + MySQL
Ilustración 4. Proceso servicio servidor web Apache + PHP + MySQL
Si nos quedamos exclusivamente con esta primera visión, sólo precisaríamos que nuestra infraestructura pudiese albergar un servidor web y un servidor de base de datos, pero por el contrario existen más servicios que podrán agregarnos funcionalidades que nos permitirán mejorar el rendimiento y facilitarán la escalabilidad horizontal.
Ya que en esta serie de artículos buscamos diseñar una infraestructura paso a paso y compartirla con vosotros, os adelantaré que nuestra aplicación web utilizará PHP y como motor de base de datos principal necesitaremos MySQL, así que podemos emplear la siguiente categorización de servicios para elegir el diseño de nuestra infraestructura.
- Balanceadores de carga (Frontales): HAProxy, NGinx, Apache
- Balanceadores de carga (MySQL): ProxySQL2, MySQL Proxy, HAProxy
- Servidores web: Apache, Nginx, LiteSpeed
- Proxys / Caché (Servicios frontales): Varnish, Nginx, Apache
- Almacenes de datos / Caché: MongoDB, Redis, Memcache
- Bases de datos SQL: MySQL, PostgreSQL
- Indexación o búsqueda: ElasticSearch, Apache Solr
Esta categorización de servicios podríamos estandarizarla para cualquier plataforma que pretendamos escalar de manera horizontal haciendo una representación por capas como podemos ver en la siguiente ilustración.
Estructuración por capas
Una gran parte de las plataformas web que podamos tener que diseñar, encajarán muy bien en una estructura de dos capas en la que separaremos el servicio de base de datos para que no afecte por necesidad de IOPS a otros servicios. Pero, por ejemplo, en un mismo servidor podríamos encajar un servicio de caché y servidor web, restringiendo o configurando correctamente los valores de uso de memoria para que nuestro servidor web no se vea afectado ante posibles picos; aun así, nuestra recomendación es que si tenemos la más pequeña idea de que el proyecto escale utilicemos un mínimo de tres capas.
El enfoque de utilizar sólo dos capas puede funcionar de manera correcta hasta que, o bien, necesitemos servicios de indexación, para lo que tendríamos que agregar una nueva capa y no combinar esos servicios en los servidores que empleamos para nuestro motor de base de datos (ambos servicios emplearán RAM y un elevado acceso a disco), o bien, el número de peticiones atendidas por nuestro frontal sean elevadas y comencemos a requerir de servicios de balanceo o escalabilidad horizontal en la capa frontal.
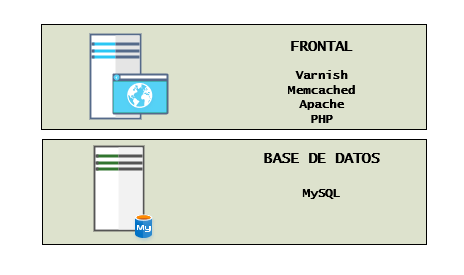 Ilustración 5. Estructura en dos capas
Ilustración 5. Estructura en dos capas
En la siguiente ilustración podemos ver una estructura multicapa que nos permite una escalabilidad, tanto vertical como horizontal, en la que si es cierto que cada una de las capas deberá estar formada por un mínimo de dos servidores, a excepción de la capa de base de datos, que esa la trataremos en otro artículo y explicaremos el motivo de la necesidad de tener un mínimo de tres servidores.
Cada capa se diseña con un mínimo de dos servidores, por los principios de alta disponibilidad que comentamos en el primer apartado. De esta manera, los servidores que están dentro de cada capa disponen de una replicación de datos o un almacenamiento clusterizado que permita la tolerancia a fallo de uno de los miembros de la capa y, cuando todos están activos, se realice un reparto de la carga o peticiones que deban atender.
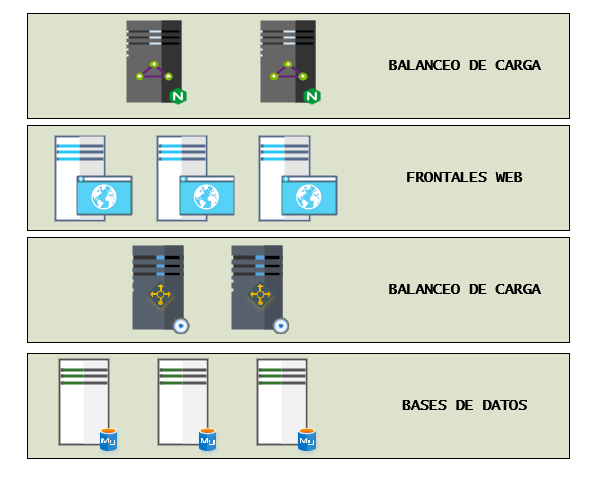 Ilustración 6. Estructura multicapa
Ilustración 6. Estructura multicapa
Al contrario que en otras distribuciones o estructuras multicapa, nosotros consideramos importante agregar encima de la capa de base de datos otra capa de balanceo por si llegásemos a precisar una estructura de base de datos multi-cluster que nos permita, por ejemplo, tener en uno de ellos una información analítica y en otro una información operativa.
Comunicación entre capas
Normalmente cuando hablamos de segregar redes, pensamos exclusivamente en temas de seguridad y nos acostumbramos demasiado a configurar que los servicios escuchen en cualquier dirección IP que tengan disponible (0.0.0.0), pero la realidad es que nos permitirá obtener un mejor rendimiento al utilizar cada interface de red para su cometido. Por tanto, no nos deberá preocupar el tener que dotar a un mismo servidor de diferentes interfaces de red que nos permitan una comunicación exclusiva para cada necesidad.
Podríamos definir que para la estructura multicapa que vimos anteriormente necesitaremos las siguientes redes:
- DMZ
- Servicios Web
- Servicios de base de datos
- Monitorización
- Backup
La definición de redes se podría ampliar algo más, pero esta sería una posible aproximación en la que cada servidor dispondrá del número de interfaces de red suficientes para las funciones que deba realizar y con visibilidad única sobre las capas / redes que precise; asegurando de esta manera que el tráfico de red que pasemos por cada direccionamiento sea el estrictamente necesario y permitiéndonos así, configurar de una manera más sencilla las reglas en nuestros firewalls.
El diseño
En esta serie de artículos, comenzaremos trabajando con este primer diagrama que iremos adaptando y ampliando a medida que avancemos, para así poder ir explicando en cada punto los motivos de cambio, agregación de nuevos servicios o su separación a otros servidores.
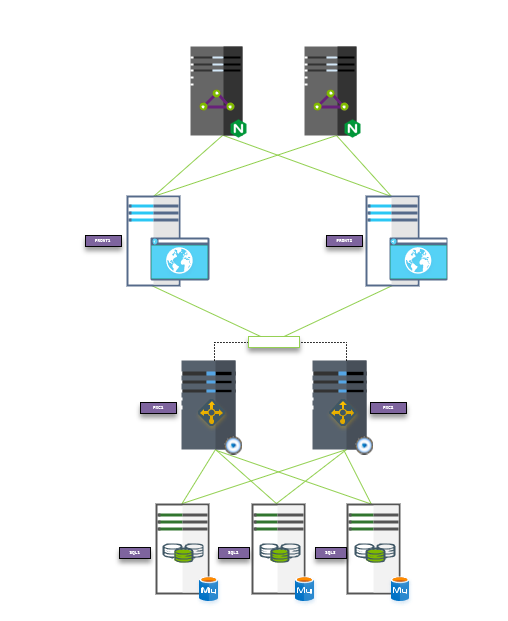 Ilustración 7. Diagrama
Ilustración 7. Diagrama
Analizando el diagrama, en la primera capa hemos definido dos balanceadores que repartirán la carga entre los servidores web que elijamos por rendimiento, la siguiente capa estará compuesta por un servicio que así mismo se define como mucho más que un balanceador de carga para MySQL (os enamorará) y, por último, nuestro cluster de base de datos MySQL.
Próxima entrega
Para los lectores más intrépidos e impacientes os adelantamos la temática de la siguiente entrega:
- Eligiendo el servidor web con mayor rendimiento: Realizaremos pruebas con los servidores Web Apache, Nginx y LiteSpeed, mostrando los diferentes resultados que se obtenga con cada uno de ellos y comprobando cuál se ajusta mejor a nuestras necesidades.