¿Cómo entiende un Bot? NLU en Rasa
Como ya hemos visto anteriormente en nuestro post sobre chatbots, Rasa cuenta con una base que se divide en dos principales patas: la parte de NLU (Natural Language Understanding), y la del Core.
En esta última, es importante saber que el Bot se encarga de decidir qué acción tomar en base a cómo se ha llegado a ese punto de la conversación. Sin embargo, a través de este post, pretendemos profundizar qué es el NLU y cómo un Bot es capaz de entender y extraer información del usuario.
¿Qué es el NLU?
Se trata de una rama del NLP (Natural Language Process) que se dedica, entre otras cosas, a que la “máquina” sea capaz de entender el significado de una frase.
En los chatbots es un parte fundamental, ya que predecir correctamente la intención del usuario nos permite poder actuar de manera más “inteligente”, y evitar el ya típico: “no le he entendido, ¿podría repetirlo?”. A estas intenciones, propuestas o peticiones del usuario, que la máquina debe clasificar, les denominamos “Intents”.
Por otro lado, es importante tener en cuenta toda la información clave de un texto, como nombres propios, fechas, productos, organizaciones, lugares o cualquier cosa que queramos extraer del texto. A este concepto le denominamos “Entities”.
Para diferenciar los intents de los entities, podemos verlo más claramente con el siguiente ejemplo:
– Me gustaría hablar con Vodafone.
En este caso, el entity sería empresa=Vodafone, y el intent, solicitar una llamada.
Flujo del NLU en RASA
En Rasa, el pipeline del NLU es definido a través del fichero ‘config.yml’. Se trata de una secuencia de pasos que se deben seguir para poder llevar a cabo la extracción de entities y la clasificación de intents. A continuación, se pueden ver los principales componentes del pipeline:
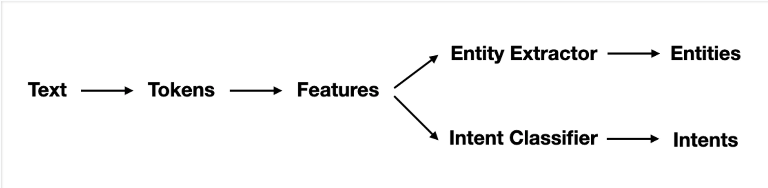
Tanto para la clasificación de los intents, como para la extraccion de las entities, se usan modelos de Machine Learning. Estos necesitan una representación numérica del texto, por lo que son necesarios un par de pasos previos: los tokens y las features.
1. Tokens:
Definimos tokenizar al proceso de separar el texto en palabras, caracteres o subpalabras. Estas pequeñas piezas de texto las denominamos tokens, y se trata de un proceso fundamental en cualquier tarea a realizar en el ámbito del NLP.
Existen diferentes maneras de tokenizar. El ejemplo más sencillo consiste en separar el texto mediante espacios en blanco y así conformar palabras. A este proceso se le suele añadir la eliminación de signos de puntuación u otros símbolos. Este tokenizador es habitual verlo en chatbots de lengua inglesa, pero en castellano no es lo más recomendable debido a la complejidad del lenguaje. En Rasa se define en el pipeline como WhiteSpaceTokenizer.
EJEMPLO:
«La tokenización es una parte fundamental en el NLP!”
[‘La’, ‘tokenización’, ‘es’, ‘una’, ‘parte’, ‘fundamental’, ‘en’, ‘el’, ‘NLP!’]
Otro de los tokenizadores más usados en el mundo de NLP que tenemos disponible en Rasa es el que nos proporciona la librería spaCy.
[‘La’, ‘tokenización’, ‘es’, ‘una’, ‘parte’, ‘fundamental’, ‘en’, ‘el’, ‘NLP’, ‘!’]
Los tokenizadores nunca modifican el contenido del texto, simplemente lo separan en piezas más pequeñas (tokens). Mediante la lemmatización de los tokens podemos añadir información que puede ser útil a posteriori. Esta consiste en relacionar una palabra flexionada (plural, feminino, conjugado..) con su forma canónica (lema). Es decir, un lema es la forma que tienen las palabras en la entrada de un diccionario tradicional.
[‘el’, ‘tokenización’, ‘ser’, ‘uno’, ‘parte’, ‘fundamental’, ‘en’, ‘el’, ‘NLP’, ‘!’]
2. Featurizers
Una vez que se tienen los tokens de cada frase debemos representarlos en forma vectorial, ya que nuestro fin es poder aplicar algún algoritmo de Machine Learning y para ello necesitamos una representación numérica del texto. También es conocida como word embedding y los modelos usados como modelos de lenguaje, aunque también se pueden usar otras técnicas que veremos más adelante.
En Rasa se pueden diferenciar dos tipos de featurizers, los primeros realizan una representación vectorial por cada token, donde tendremos una matriz de dimensión n.º tokens x features, los segundos, representan la frase completa, donde la matriz será 1 x features.
Los featurizers más usados en Rasa son los siguientes:
- RegexFeaturizer
Crea un vector de características para cada mensaje del usuario y sirve tanto para clasificación de intenciones como para la extracción de entidades. Utiliza expresiones regulares que nos proporcionan información en forma de vector si hacen “match” o no.
- CountVectorsFeaturizer
Crea una representación bag-of-words (ignorando el orden de las palabras). Se basa en el algoritmo de scikit-learn CountVectorizer y se usa para clasificación de intenciones y toma de decisiones.
- SpacyFeaturizer
Crea un vector de características para extracción de entidades, clasificación de intenciones y para la toma de decisiones. Puede crear el vector de la frase a través de la media o por max pooling.
- LanguageModelFeaturizer
Crea características para la extracción de entidades, clasificación de intenciones y toma de decisiones, usa un modelo de lenguaje pre-entrenado. Suelen ser modelos complejos que necesitan mayor cantidad de recursos, y aunque normalmente tienen mejor rendimiento, pueden pecar de overfitting. Podemos usar cualquier modelo de la librería HuggingFace, siempre que sean compatibles con el idioma de nuestro bot. Entre ellos se encuentran modelos muy conocidos como BERT, GPT y RoBERTa.
Con este tipo de modelos, se intenta darle contexto a las palabras para dotar al bot de inteligencia. Así, las palabras que tengan un significado parecido, en función del contexto, su representación vectorial se encontrará próxima en el espacio de características.
Una vez tenemos los tokens y frases representadas en forma vectorial, debemos entrenar un modelo de Machine Learning para poder dotar al bot de capacidad de entender al usuario y extraer la información relevante.
3. Clasificador intenciones
- SklearnIntentClassifier
La librería de python scikit-learn nos proporciona un clasificador que podemos usar con Rasa para clasificar las intenciones. El algoritmo que hay por debajo es un support vector machine (SVM), que utiliza un método grid search para optimizar los hiperparámetros. Podemos configurar los hiperparámetros (C, kernerl, gamma, etc.) en forma de lista y, mediante este método, obtener el mejor modelo que se adapta a nuestros datos.
- DIETClassifier
Por sus siglas en inglés Dual Intent Entity Transformer, sirve tanto para clasificar intenciones y extraer entidades. Como se puede ver en la imagen tiene una arquitectura compleja basada en transformers.
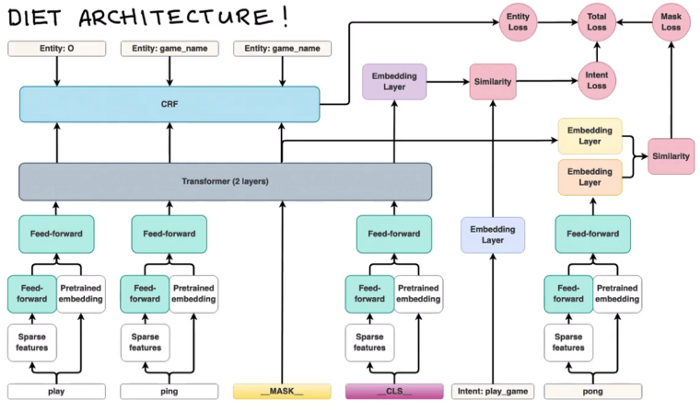
Como se observa, existen tres funciones de perdida diferentes: entity loss, intent loss y mask loss. Ya conocemos que son entity e intent, pero hasta ahora no se ha mencionado que es “mask”. Es una de las tareas más utilizadas en el mundo del NLP, dado que nos proporciona un modelo de lenguaje. Esta consiste en que, a partir de una serie de tokens, se predice el siguiente token (mask) que mejor encaja. Son modelos self-supervised y nos valen de base para poder realizar otro tipo de tareas.
Volviendo al DietClassifier, ¿por qué usamos token-mask y otro modelo de lenguaje si ya estábamos usando modelos preentrenados (recordemos BERT, GPT..)?
Pues las respuesta está en que, de esta manera, permitimos que el modelo se adapte mejor al dominio de nuestro dataset. Teniendo en cuenta que en el contexto de un chatbot pueden existir jergas, palabras mal escritas u órdenes, entrenando de nuevo un modelo de lenguaje nos permite capturar el dominio específico.
Esta arquitectura está diseñada para permitir que el modelo aprenda una representación general de las frases de entrada. Durante el entrenamiento, se tienen en cuenta las tres funciones de perdida previamente mencionadas: entidad, intención y máscara. Así, el modelo no se limita a aprender una tarea en concreto, sino que puede generalizar sobre las tres.
4. Entity Extraction
Si bien el DietClassifier sirve para extraer entidades, RASA nos permite el uso de otros métodos para atacar este problema. Por ejemplo, para entidades que se puedan reconocer fácilmente mediante un patrón específico (DNI, números de teléfono, emails…) se puede usar el RegexEntityExtractor.
También se puede entrenar un modelo de spaCy por fuera de Rasa. Esto nos permite utilizar un gran conjunto de datos sin que tengan que estar en el dominio del chatbot. Puede resultar muy útil para entidades genéricas como por ejemplo los nombres propios o localizaciones.
Una de las ventajas de Rasa es que podemos utilizar diferentes tipos de extractores en el mismo pipeline. De esta forma podemos extraer fechas con duckling, nombres propios con spaCy, números de teléfono con regex y entidades más específicas del dominio con el DIET classifer.
El pipeline NLU de rasa tiene diferentes componentes que interactúan entre sí. El orden de los componentes del pipeline es muy importante, ya que se define como una secuencia de pasos ordenados.
Resumiendo
Podemos resumir los pasos de la siguiente manera: primero, nos llega un mensaje del usuario, después tokenizamos el mensaje. Una vez tengamos los tokens, se calculan los vectores de características, tanto para la frase completa como para cada token. Cuantos más componentes se añadan en estos pasos, más información le proporcionaremos al modelo final (ojo con el overfitting). Y por último, utilizamos estos vectores para entrenar un modelo que clasifique la intención del usuario y extraiga las entidades del mensaje.
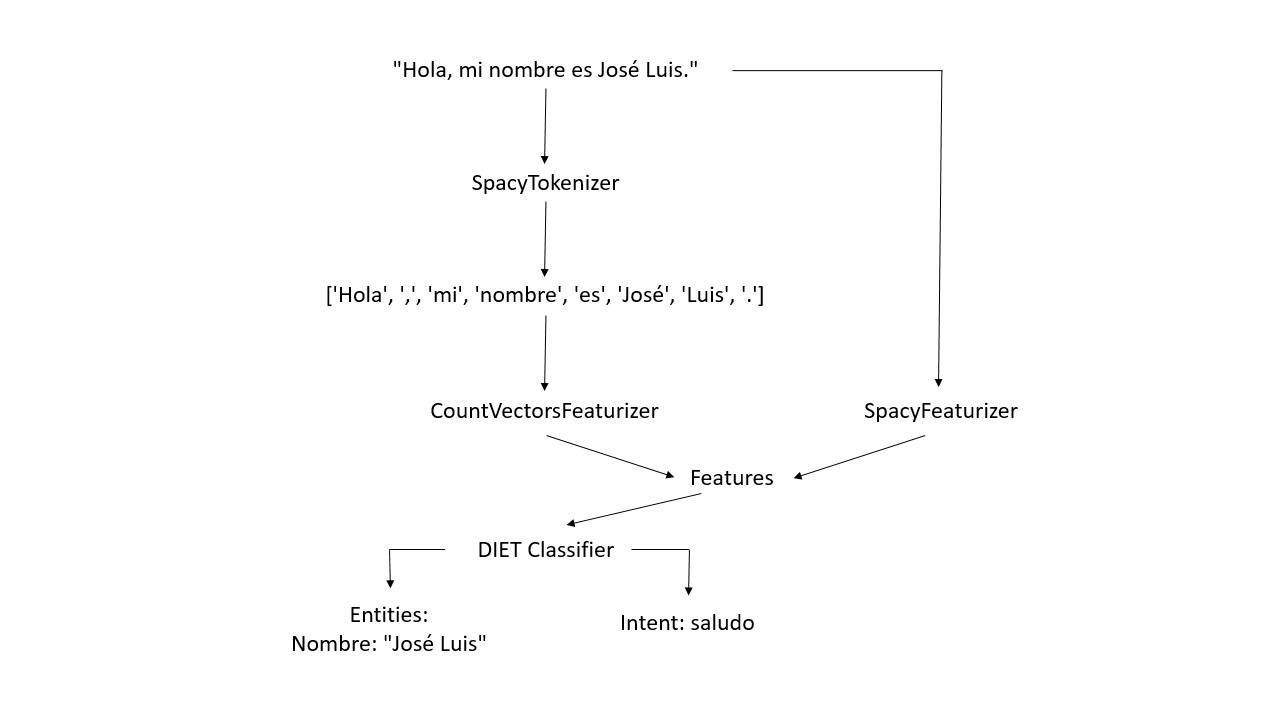
Veamos un esquema a modo de ejemplo:
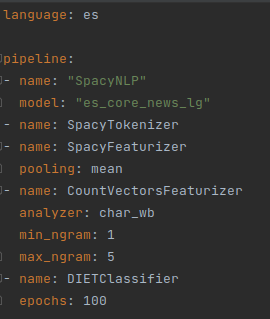
Tenemos el siguiente pipline de la parte NLU de un chatbot en castellano. Se puede ver cómo están definidos el tokenizador, los featurizers y el DIETClassifier.
Siguiendo este pipline, el siguiente esquema visualiza el flujo que sigue el texto, en la parte NLU, cada vez que un usuario habla.